HashMap 类属于 Java Collection 框架,提供了Map接口的基本实现。
HashMap 内部结构
HashMap 中需要了解的概念:
- 哈希 hashing – 一种将对象数据映射到某个具有代表性的整数值的算法。哈希函数应用于键对象以计算桶的索引,以便存储和检索任何键值对。
- 容量 capacity – 容量是HashMap中桶的数量,默认这个数量为 16。
- 负载因子 Load Factor – 负载因子是决定何时增加Map容量的度量。默认负载系数为容量的 75%。
- 临界点 threshold – 临界点是当前容量和负载因子的乘积。
- 重新哈希 rehashing – 重新哈希是重新计算已存储条目的哈希码的过程。简单地说,当哈希表中的条目数超过阈值时,对Map进行重新哈希处理,使其具有大约两倍于以前的桶数。
- 碰撞 collision – 当哈希函数为两个不同的键返回相同的桶位置时,就会发生冲突。
我们创建一个如下的 HashMap:
Map<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.put(4, "four");
此时,我们可以在 IDE 中看到 Map 的结构:
| map | {HashMap@488} |
|---|---|
| loadFactor | 0.75 |
| modCount | 4 |
| size | 4 |
| threshold | 12 |
| table | HashMap$Node[16]@507 |
| entrySet | {HashMap$EntrySet@491} size = 4 |
自定义参数
上面,我们使用默认构造函数创建了HashMap 。在接下来的部分中,我们将看到如何将初始容量和负载因子传递给构造函数,来创建一个HashMap。
自定义初始容量
创建一个具有 5 个初始容量的 Map :
Map<Integer, String> initMap = new HashMap<>(5);
此时,我们可以在 IDE 中看到 Map 的结构:
| map | {HashMap@488} |
|---|---|
| loadFactor | 0.75 |
| modCount | 4 |
| size | 4 |
| threshold | 6 |
| table | HashMap$Node[8]@490 |
| entrySet | {HashMap$EntrySet@491} size = 4 |
虽然我们指定了初始容量为 5,但是 HashMap 并没有才用我们给的值,table 的大小为 8,临界点threshold 刚好为 8*0.75=6。
创建一个初始容量为 3,负载因子 为 0.5 的 Map:
Map<Integer, String> map = new HashMap<>(3, 0.5f);
此时,我们可以在 IDE 中看到 Map 的结构:
| map | {HashMap@488} |
|---|---|
| loadFactor | 0.5 |
| modCount | 1 |
| size | 1 |
| threshold | 2 |
| table | HashMap$Node[4]@490 |
| entrySet | null |
虽然我们指定了初始容量为 3,但是 HashMap 并没有才用我们给的值,table 的大小为 4,临界点threshold 刚好为 4*0.5=2。
当我们给初始容量为 3,负载因子 为 0.5 的 Map中添加 4 个元素后结构:
| map | {HashMap@488} |
|---|---|
| loadFactor | 0.5 |
| modCount | 4 |
| size | 4 |
| threshold | 4 |
| table | HashMap$Node[8]@490 |
| entrySet | null |
可以看到,table 的大小变为 8 了,也就是扩容了,而扩容是一个耗时的行为。
原因分析
虽然随意指定初始容量和负载因子的值,不会产生异常。但是很明显,不合适的取值会导致 HashMap 产生额外的消耗。
HashMap 内部使用哈希码作为存储键值对的基础,如果 hashCode() 方法写得很好,HashMap 将把元素分布在所有的桶中。此时,HashMap 中存储和检索条目将达到固定时间复杂度 O(1)。
当元素数量增加并且桶大小固定时,就会出现问题。这将导致每个桶中装有更多的元素,从而产生较高的时间复杂度。
解决的办法是我们可以在增加元素的时候增加桶 bucket 的个数。然后,我们可以在所有存储桶中重新分配元素。通过这种方式,我们将能够在每个桶中保持恒定数量的项目并保持O(1)的时间复杂度。
合适的负载因子
在这里,负载因子帮助我们决定何时增加桶的数量。负载因子越低,空闲桶就越多,发生碰撞的机会就越少,从而使 Map 实现更好的性能。因此,我们需要保持低负载因子以实现低时间复杂度。
同时也应该注意,HashMap通常具有O(n)的空间复杂度,其中n是条目数。太低的负载因子值会增加空间开销。
当 Map 中的元素数量超过 threshold 限制时, Map的容量会增加一倍。当容量增加时,我们需要将所有元素(包括现有的和新加入的)平均分配到存储桶中。
初始化一个默认的 HashMap,初始容量是 16,负载因子是0.75,临界值为 12,当向其中添加第十三个元素后,Map 的结构:
| map | {HashMap@488} |
|---|---|
| loadFactor | 0.75 |
| modCount | 13 |
| size | 13 |
| threshold | 24 |
| table | HashMap$Node[32]@525 |
| entrySet | {HashMap$EntrySet@491} size = 13 |
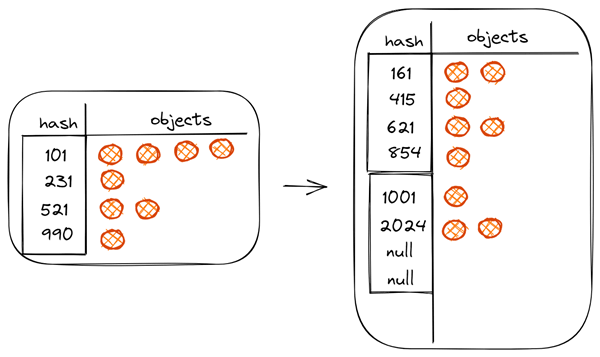
哈希冲突优化
当哈希值相同时,就出现冲突了,这会降低 Map 的性能。
最开始,Java 中的 HashMap 通过使用 LinkedList 存储出现冲突的元素。冲突元素会被添加到LinkedList的头部。在最坏的情况下,这会将复杂度增加到O(n)。
为了避免这个问题,Java8 及更高版本使用平衡树(也称为红黑树)而不是LinkedList来存储碰撞元素。这将HashMap的最坏情况性能从 O(n) 提高到 O(logn)。
HashMap最初使用LinkedList,然后当元素的数量超过某个阈值时,它将用平衡二叉树替换 LinkedList。TREEIFY_THRESHOLD 常量决定了这个阈值,目前这个值为 8,这意味着如果同一个桶中有超过 8 个元素,Map将使用红黑树来保存它们。